
本篇文章,仅为个人学习的记录。
1. C++ 基础编程
1.1 如何撰写 C++ 程序
由于之前已经学习过相关内容,就不再记录简单的知识点,在这里记录一下课后习题中几个有意思的点,并且是这解释一下。
先看一段简单的代码:
1 |
|
- 将头文件 string 注释掉会发生什么?
- 将 using namespace std; 注释掉呢?
- 将 main 修改成 mymain 呢?
问题一
与预期不同,这样做并没有产生错误信息,而是正常编译通过,运行时也没有错误。但并不代表这就是正确的!!!
可能是以下几点导致的:
- 间接包含,能在其他包含的头文件(如
<iostream>)中间接地包含了<string>。不过标准库 iostream 并不包含 string,所以可以排除这一点 - 编译器宽松设置:编译器可能在宽松的设置下忽略一些缺失的头文件声明,但这不是标准行为,可能会导致不可移植的代码。所以,请不要这么干!!!
问题二

如上图所示,产生了很多 undeclared identifier 的错误,想要在不使用命名空间的情况下解决这个问题,就要在使用标准库的名称前加上 std:: 前缀。
想要解释这个问题,需要先理解什么是命名空间参考: C++ 命名空间
问题三

简单解释一下:main 函数是程序的入口点,必须存在并且名称必须是 main。修改成其他名称后,程序仍然可以编译,但无法正常执行,因为没有定义入口点。
上面解释了为什么需要 main ,但是在执行 main 前,程序还做了许多工作,参考:# CPP程序从诞生到死亡做了什么?
1.2 对象的定义与初始化
初始化语法
为了解决 “=” 运算符无法赋多个初值的问题,引入了构造函数语法,如在标准库中的复数类,在初始化时就要写成complex<double> purei(0, 7); 表示 0 + 7i。
1.3 撰写表达式
1.4 条件语句与循环语句
1.5 如何运用 Array 和 vector
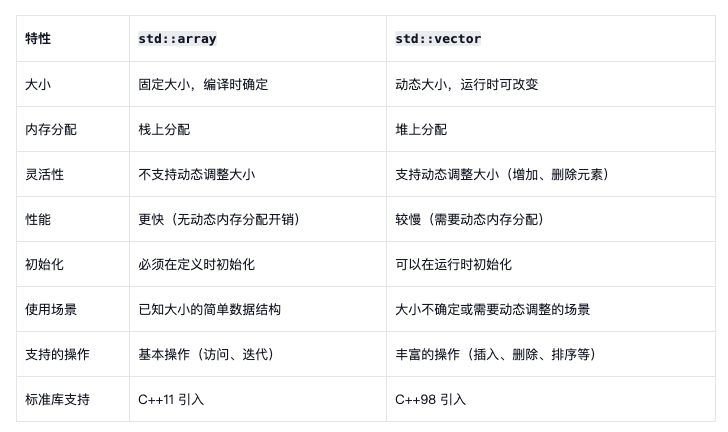
1.6 指针带来弹性
1.7 文件的读写
要进行文件的读写操作,首先得包含 fstream 头文件: #include <fstream>;
为了打开一个可供输出的文件,我们定义一个 ofstream 对象,并将文件名传入:
1 | // 1. 打开文件并清空 |
如果指定文件不存在,则创建文件并用于输出,如果存在则打开进行输出。
2. 面向过程的编程风格
2.1 如何编写函数
一个函数由四个部分组成:返回类型、函数名、函数体和参数列表。
2.2 调用函数
在这一部分,需要关注一个很重要的问题,参数的传递方式:传址和传值
传值
首先看一下,下面的代码:
1 | void swap(int val1, int val2) { |
这个代码非常的容易理解,作用就是将 val1 与 val2 交替,然而我们调用这个函数执行却会发现,并没有达到我们想要的结果。
如果使用调试器去单步调试会发现,swap 函数被正常执行了,所以问题是出现在了传递方式或者返回值上。在这里,我们主要讨论传递参数。
事实上,在上面的代码中,调用 swap函数时,对象进行了一次复制,而原对象与副本就不再有任何关系了。
当调用一个函数时,会在内存中建立起一个特殊区域,称为“程序堆栈”。这块特殊区域提供了每个参数的储存空间,也提供了函数所定义的每个对象的内存空间——我们把这些对象称为 local object(局部对象)。一旦函数完成,这块内存就会被释放掉,或者说从程序堆栈中 pop 出来。
传址
这种传参方式就是“传值”。为了解决这一问题,需要使用另一种传参方式:“传址(pass bu reference)”。
1 | void swap(int &val1, int &val2) { |
& 是取址符,其实我们看一下传址的英文名称:pass by reference。reference 是引用的意思,也就是一个变量的别名。所以说这种传递方式本质上是给原参数起了一个别名,对象本身不会进行复制,而是复制了原参数的地址。
这种传参方式还有一个显著的优点,由于不会复制对象,在对象内存较大时,它可以节约内存空间,提高性能。但是如果我们不希望参数被修改,就要加一点防护措施,使用 const 关键字进行修饰,如下面的代码:
1 | void display(const vector<int> &vec) { |
传指针
与传地址区别不大,只是写法上有细微区别。
2.3 提供默认参数值
2.4 使用局部静态对象
2.5 声明 inline 函数
inline 函数是一种建议编译器将函数代码直接插入到调用点的优化技术,这样做减少了函数调用的开销,避免了常规函数调用的栈操作和跳转。
- 使用场景:通常用于短小的函数
- 编译器建议:
inline只是对编译器的建议,编译器可能会根据具体情况决定是否真的将函数内联。
2.6 提供重载函数
为了解决参数列表不同(参数类型不同、个数不同)引入了函数重载。由编译器根据传入的实际参数与每个重载函数进行比对,来选择调用重载函数。
2.7 定义使用模版参数
1 | template <typename elemType> |
函数模版(function template) 以关键字 template 开场,紧接着以成对的<>包围一个或多个标识符。这些标识符用来表示我们希望推导决定的数据类型。
标识符事实上起到一个占位符的作用。
函数重载与模版的区别:
一般来说,如果函数根据传入参数不同,具备多种实现方式,可以选择函数重载。如果希望函数主体代码不变,仅仅改变其中的数据类型,可以使用函数重载。
2.8 函数指针带来更大的弹性
太抽象了,看个视频吧:指针函数与函数指针
2.9 设定头文件
头文件中通常声明了类、函数、常量等信息。向其他文件暴露接口,以便文件引用。
3. 泛型编程风格
Standard Template Library(STL) 主要有两种组件构成
- 容器:vector list set map……
- 泛型算法:find() sort() replace() ……(泛型指算法与算法想要操作的元素类型无关)
3.1 指针的算术运算
首先看一段代码,如下:
1 | int min( int array[24] ); |
这个函数似乎要求输入的参数是一个由24个元素的 array ,并且以传值的方式传参。事实上,这两个加上都是错误的,array 并不会以传值的方式复制一份,而且可以传递任意大小的 array 给 min()。
这是因为,当数组被传递给函数时,或是由函数返回,本质上仅有第一个元素的地址被传递。所以上面的函数声明可以写成:
1 | int min( int* array) ; |
即使我们传入的是一个 array 的首地址,但是仍然可以使用下标运算符array[i] 来访问元素,因为下表运算符本质上就是起始地址加上偏移量,计算得到元素地址。
3.2 了解 Iterator(泛型指针)
类似但不完全等于传统指针。迭代器(泛型指针)是在底层指针的基础上提供了一层抽象,取代程序原本“指针直接操作”的方式,适用于不同容器。
至于这个抽象层是如何实现的,说实话,我没看懂……看个视频吧:几分钟听到迭代器
3.3 所有容器的共通操作
3.4 使用顺序型容器
3.5 使用泛型算法
search():比对某个容器中是否存在某个子序列。如,在 {1,3,5,3,2} 查找 {3,5,3},它会返回 1,即子序列起始处。
3.6 如何设计一个泛型算法
- Function Objects:算术运算,关系运算和逻辑运算
- 算术运算:plus
3.7 使用 Map
map 按键查找:words.find("findTarget"); 该语句会返回一个 iterator,没有则返回 end()。
另一种方法是,使用 count(),如words.count("findTarget"); 该函数返回 findTarget 的个数。
3.8 使用 Set
对于任何 key 值, set 容器只存储一份,换言之 set 不会存储相同的对象。
且 set 容器默认使用 less-than 排序。
3.9 如何使用 Iterator Inserter
没看懂……
3.10 使用 iostream Iterator
4. 基于对象的编程风格
4.1 如何实现一个 class
如果函数在 class 主体中定义,或者说在函数声明时定义(在头文件中),这个成员函数会自动被视为 inline 函数。
4.2 什么是构造函数和析构函数
Member Initialization List (成员初始化列表)